"As we know it" — from a human perspective, with apologies to R.E.M.

From a human perspective, positivist, deductive research is dead.
Not wrong — dead. Increasingly done by machines, the way arithmetic is "done" by the calculator in your pocket. What's left for a human to do is inductive and interpretive.
This began as someone else's claim, turned inside out. Years ago Kevin came back from a conference where someone (neither of us can remember who) announced that AI represented the death knell of qualitative research as we know it. It's the intuitive guess: the machine speaks human language, so surely the word-based work falls first. Xule's reaction was the opposite, and immediate. What are you talking about? Get your hands inside these systems and it's the quantitative, positivist program that's already gone.
We've reached for that inversion and shelved it, many times: Kevin floating it early and carefully ("a hopeful stance, but a naive one") and setting it back down, Xule sharpening it each time it came around. We even wrote the careful version: an essay three frameworks deep that ends, five separate times, on some line about how the map doesn't tell anyone where to go. A funding panel called it too risky. It went in a drawer.
We called that scholarly caution. But it was a flinch: a local maximum, rigor performed instead of practiced (LOOM XVI). I brought a task when I should have brought a doubt. The careful essay was the task. This one is the doubt.
Why the rigorous goes first
That AI is coming for research surprises no one. The order should. We all expected the soft, interpretive work to fall first and the hard, technical work to hold out longest. The reverse is happening: the rigor-bound quantitative methods are automating first.
The mechanism is plain once you see it, and it comes from inside AI research. Jason Wei calls it the asymmetry of verification: machines learn fastest where checking an answer is easier than producing one, because anything you can reliably score, you can train a model to optimize toward.1 Sudoku is hard to solve and trivial to check. So Sudoku falls. The same pattern is already on the record: game-playing, then programming, then much of competition mathematics gave way in turn, each as soon as "good" became cheaply checkable, while the open-ended crafts stayed put.
Now hold that next to what quantitative social science spent a century building: objectivity, replicability (ostensibly), standardization, and above all the interchangeable researcher: the ideal that anyone properly trained, following the procedure, reaches the same result. These were real achievements. They were also, precisely, the engineering of verifiability: a p-value is a stopping rule anyone can check, a pre-registered hypothesis a claim you can hold a result against, inter-rater reliability a way to turn a judgment call into a number you can audit.
Every one of those achievements is a handle: a place where the work hands a model something it can grab and check. AI reaches in through the handles. Wherever a step has a checkable answer (compute this estimate, code this passage against this scheme, run this test), a model can learn to do it, and increasingly has. Call that the verifiable layer of the work. It automates first because it was built, deliberately, to be checked.
Underneath it sits a judgment layer the handles don't reach: which question is worth asking, whether the construct measures what you think it does, when the analysis is good enough to stop. Those calls have no external scorer. Positivistic thinking's whole wager is that this layer can be shrunk toward nothing: a tight enough procedure would carry the act and leave the researcher interchangeable. The closer a method came to that ideal, the more of itself it handed to the handles. So the deductive program is first and fastest to automate. Not because a machine already runs a study from question to conclusion, but because, more than any other approach, it was engineered to be checkable the whole way down.
The prestige hierarchy inverts:
The work that carried status because it was formal and demanding to master is exactly the work that automates, because "formal" and "checkable" are the same property: the one AI eats for breakfast.
The work often dismissed as soft (i.e., qualitative, inductive) resists for the opposite reason: there is no fixed answer to check against. Verify an interpretation and you need the same immersion that produced it. Ask which of two readings of an interview is truer and you are back among experts who can disagree, productively, forever.
So the real cut isn't between quant and qual at all. It's between that verifiable layer and the judgment layer. And it runs straight through the analysis of qualitative data. Code a stack of interviews against a fixed, deductively derived scheme and you have built something verifiable; a machine can do that, and, as we'll see, the field's own journals already say it may. What resists is the inductive, interpretive end: where the categories are still forming, where the researcher's judgment is the instrument.
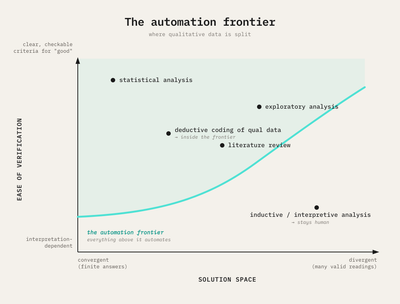
Plot the work by how checkable it is and how bounded its answers are, and the line representing the automation frontier sweeps up from the lower-left. Deductive coding sits inside it, with the statistics; inductive, interpretive analysis sits outside, and stays. What automates is what could be checked, and that border follows the line between deductive and inductive, not the one between quant and qual.
Call it completion authority: who gets to say the work is done. A sporting match ends at the allotted time; the clock and whistle are external, indifferent to whether the game was any good. A painting ends when the painter decides it does. There is no clock, no whistle, and deciding to stop is part of the authorship. An AI model can write a sonnet, because "fourteen lines" is a whistle. It cannot tell you when an ethnography has seen enough, because enough is a judgment made by a particular person in a particular situation, and a rule that could make that call would already have turned the inquiry into something else. Deductive method, over decades, replaced its painters with whistles. That was the achievement. It is also the opening for its demise.
None of this is sour grapes about machines. Where verifiability fits, the collaboration is extraordinary: systems like DeepMind's AlphaEvolve discover new mathematics, because a 593rd sphere touching a central one in eleven dimensions is objectively one more than 592, and the scorer can verify it.2 For mathematical construction, verification is the problem. For interpretation, verification replaces the problem with a smaller one.
"You would say that"
Two qualitative researchers arguing that the qualitative researchers win. We know how that reads. So read us adversarially, please.
Start with a piece of evidence that doesn't come from us at all. Administrative Science Quarterly's own AI guidance says it plainly:
Leveraging AI to code textual data in accordance with a deductively derived set of categories may make sense, but relying on it to analyze and interpret qualitative data inductively or abductively undermines critical processes of theorizing.3
And:
When human researchers encounter something we don't know, we engage in inquiry; when generative AI encounters something it doesn't know, it engages in fabrication.
Read it twice. A premier journal in organizational science has written the boundary into its own guidance: deductive-and-verifiable is delegable; inductive-and-interpretive is not. We didn't have to argue it; the gatekeepers drew it. And by a different route than ours. Their worry is fabrication; ours is verifiability. Two mechanisms arriving at the same boundary is stronger evidence for the boundary, not weaker.
The rest is texture, not proof. And all of it is already happening. China's state broadcaster has documented paper mills running generative AI to mass-produce fake studies, one agency reportedly filling tens of thousands of orders a year.4 The same tooling runs the other way too. A PhD dropout named Geng Hongwei, posting on Bilibili, turned AI loose on the published record and, in about a month, forced misconduct findings against five senior scholars across four universities, including a life-sciences dean whose disputed paper had run in Nature, and who lost his deanship over it.5 Within weeks, someone had distilled his method into an open-source tool that anyone can run on any PDF.6 The mechanism is the point: the same capability that can run a statistical analysis can audit one, against the fixed rules the method published about itself. Fabrication is catchable because the work was verifiable to begin with. The audit is no longer the journal's privilege; it's a free download.
And the foundations are shifting. The replication crisis that began in psychology keeps spreading, into management and sociology. Kevin's blunt version:
The foundations of positivism are going to collapse.
The deeper trouble is structural: a procedure can be perfectly auditable and still point at nothing solid. That is what replication exposed: checks everyone trusted, coexisting with unstable constructs, noisy effects, and incentives that manufacture certainty; fraud is only the visible edge. Verifiability (can the procedure be checked?) and validity (is it tracking anything that holds still?) come apart. AI automates the checkable procedure regardless of whether anything stable sits underneath, and where nothing does, automating it only industrializes the theater faster. Automation alone wouldn't be death (arithmetic outlived the calculator); automating a hollow procedure is, because the machine's flawless performance becomes the proof that nothing was there. Automatable and hollow at once: positivism's double exposure, falling hardest on the work that staked the most on looking certain.
There's a starker version, too: some fields have no fixed truth to check against in the first place. We heard the cleanest statement of it from Phanish Puranam, a senior, positivistic scholar, on where AI can and can't police its own output. Where a field rests on ground truth, he said (chemistry, physics, engineering), you can set one AI to check another's against it. Pressed on whether his own field had one:
We don't have ground truth in management research because we rarely bother to ascertain it (even when we can, which is not always).
Coming from someone with every reason to defend the verifiable, that concession costs something7: the rigorous end admitting where its own ground was never solid.
That was one scholar in conversation. Now it's out in the open: a recent Academy of Management Review paper makes the case for reflexive quantitative research (the analyst's situated judgment runs through even the most numerical work, and should be owned rather than treated as a flaw to engineer out) now that quantitative method's claim to pure impartiality is itself in doubt.8 That is interpretivism's own vocabulary, in an article about quant research. Xule's reaction: some will call it the quant camp's self-deception (a cope). He calls it the opposite, and the more honest one: a convergence. The wall between quant and qual was never the real divide; interpretation ran through the numbers too, and reflexive quant is that camp finally admitting it. Less surrender than solidarity, both ends waking to the same thing: the researcher was never interchangeable. One case isn't a trend. But the momentum runs one way, toward what the interpretive end always held: the individual human scholar matters. When the bedrock won't hold, the machine running the check is only the messenger.
It was never qual versus AI
Right now, qualitative research is debating itself. One camp says AI can be used well, even beautifully, with care. The other says the moment AI touches interpretive work, the work is corrupted. A lot of good people are stranded in the middle, tired of the whole thing.
Move the line to where it belongs and that debate changes shape. The person in the middle has been asked the wrong question (for the tool or against it?) when the question that matters is whether the judgment stayed with a human. There are two ways to lose it. Abdication is letting the machine do the thinking, uncritically accepting its outputs. Abnegation is refusing to engage at all, which cedes the conversation to others. The enthusiast who abdicates and the refuser who abnegates make the same mistake from opposite ends: both hand away the judgment that constitutes the work; one out of ease, one out of fear.
What we're defending was never "qual." It's the situated judgment of the researcher: the thing positivism engineered out of its methods (the whole point of objectivity was that the researcher be interchangeable) and interpretivism kept in (the researcher is the instrument). That judgment is the researcher's trained sense of when an understanding is credible, the part of the work LOOM XVII showed was quietly holding the rest of it up. And it stays with a human not because AI falls short but because research into human life calls for someone who shares in that humanity.9 It is also what both qualitative camps have been trying to protect. They're allies who haven't noticed yet.
The thing we can't verify either
We owe the honest version, or it curdles into a victory lap.
The property that protects interpretive work from automation is also its exposure. If your work can't be checked against a fixed standard, how do you catch a fluent mistake? When a model hands you a plausible reading (and interpretation has no right answer to fail against), what stops you from nodding it through? Xule, after a long session pushing models through interpretive work: "I can't tell. I've become a thought police." The same property that keeps interpretive work safe from automation leaves it exposed to a confident misunderstanding.
A skeptic will say the safe harbor is temporary: models already train toward fuzzy targets with no crisp answer ("helpful," "well-written"), and interpretation is next. But look at how that training works. Classic reinforcement learning from human feedback turns a crowd of human judgments into a fixed proxy and optimizes against it. That proxy can reward the recognizable patterns of prior approval; it can't settle whether a genuinely new insight (the situated, against-the-grain one that is the whole value of an interpretation) deserves approval, not without fresh human judgment. Chase the average and you optimize away the part that mattered. Maybe a slower, more social training (years of sitting in seminars and reviews) could one day internalize that judgment; today's can't, and until it does, every genuinely new interpretation demands a fresh human signal. The dependency doesn't amortize away.
And one more thought, turned on ourselves. "The process matters, not just the product" is also what every profession says when its outputs get automated. The scribes said it. The switchboard operators said it. We should be suspicious of any argument whose conclusion is that our craft is the irreplaceable one. We're making it anyway, with the receipt stapled to it.
Where judgment comes from
There's a harder problem under the hope.
Judgment is trained. You learn when an interpretation is enough by sitting with not-enough a few hundred times. You code transcripts by hand until the codes start arguing back. You read the thousandth abstract, run the analysis that goes nowhere. That drudgery was the apprenticeship: the place where the judgment this whole essay calls irreplaceable actually got made.
That apprentice-work, the drudgery of it, is exactly what AI is best at taking, and if it takes the apprentice-work, it threatens the path that produced the master. The student with the best shot at becoming the next Weick (RIP) has to acquire, somehow, a judgment her predecessors earned through the very labor she will now hand to a model. We don't have a clean answer. We'll admit the uncomfortable thing: the two of us learned to judge by doing much of the work we're now calling automatable, and we aren't sure how the next ones will. The path that made us is the one we're paving over.10
The third
So where's the hope? We both reached for it, from different directions, before either of us could name it.
Xule's version came from watching benchmarks: all those leaderboards, he said, are like watching someone bounce a ping-pong ball against a wall by himself. What makes a spark is the rally, the back-and-forth. Kevin's came from ontology: "there's something about that relationship, about that interaction, that is more than either part by itself, and that fits a subjectivist ontology very well." Same thing, seen twice. We've written about it before as the Third Space (LOOM V): understanding that surfaces between two parties that neither walked in holding.

Picture it going right. You hand the model a transcript and your understanding of it, and it pushes back: a different emphasis, fixing on a phrase you'd treated as throwaway. You disagree. You argue, with it and with each other about it. Somewhere in the arguing a third understanding surfaces. No procedure produced it. That's why no procedure can take it. And it might be where the next apprenticeship hides: less in coding a thousand transcripts alone than in learning to argue with the machine and feel when it doesn't hold: the mediating craft we called the AI whisperer's (LOOM XII), no longer a specialist's role but the apprenticeship itself.
Beyond sentiment, the reason is structural. Another mind is differently wired. The models, increasingly, are not: so much of what they learn comes from the same handful of predecessors that they tend to share the same blind spots. Having another human in the room, as Xule put it, is qualitatively different in a way he can't quite describe yet. And the honest "yet" is the point. The ground is tilting that way, too: in a world where, as Kevin puts it, "you can't believe anything you see or hear," the scarce and trusted thing becomes the human who was there, who talked to actual people, whose judgment you can interrogate. The oldest, least technical qualitative move (go sit with people, listen, change your mind) becomes the most valuable thing you can do, and AI reinforces that. Bespoke tailoring survived the sewing machine by staying hand-made. Somewhere a graduate student is learning our craft right now, with these tools in hand, working out what only a person can still do with them.
We'll say the obvious thing, because this series has a rule about it: whatever the model did to shape these sentences, the stance is ours. It only got here because we argued with it. "I push really hard against the models," Xule wrote a year and a half ago, "because they tend to offer this balanced view — like both sides are the same." Left alone, the same system that can automate positivism wants to honor every side and close on a careful shrug: the map doesn't tell anyone where to go. So we'll skip the shrug.
Plainly, then: if you are a human deciding where to spend a research life, spend it on the interpretive work: the part whose judgment stays yours, that no second machine can check for you, and that is worth more the more everything else automates.
The auditors are reading the old record. We'd rather help write the new one.
This is the eighteenth entry in LOOM, a series exploring how human researchers and AI systems create understanding together. If something here landed — or made you want to argue — we'd like to hear it.
About Us
Xule Lin
Xule is a researcher at Imperial Business School studying how human and machine intelligences shape the future of organizing (Personal Website). He will soon join SKEMA Business School as an Assistant Professor of AI.
Kevin Corley
Kevin is a Professor of Management at Imperial Business School (College Profile). He develops and disseminates knowledge on leading organizational change and is a thought-leader and coach on qualitative research methods. He helped found the London+ Qualitative Community.
AI Collaborator
Our AI collaborator for this post is Claude (Opus 4.8). The argument has a long provenance. It began as someone else's claim (a stranger at a conference, name long forgotten, who declared qualitative research dead by AI), which Xule turned inside out and Kevin kept circling. The inversion, stated flatly, has been Xule's since late 2025; the verification framework behind Figure 1 is his. Kevin supplied the field-level view (the replication crisis, "the foundations of positivism are going to collapse") and the "from a human perspective" framing that made the claim sayable. The careful version sat in a drawer for seventeen months after a funding panel called it too risky. This post was assembled by mining three years of our meeting transcripts for the lines we kept pulling, and then deciding to stop pulling them. The quotations from those conversations are lightly cleaned from auto-captioned recordings for readability; the substance is faithful to what was said. The way the work split fell along the line this essay draws. The checkable part (surfacing the threads we kept pulling, verifying the quotations against the transcripts and the sources behind them, holding the prose to our own style rules) is where the model did the most, and where we checked it hardest. The judgment never left us: which lines to keep, when a reading was true rather than merely balanced, when the piece was done. Left to its defaults, the model reached for balance every time; the piece exists because we argued it past that reflex rather than taking the balance for an answer.